当今时代人工智能都已经是烂大街的词了,OCR 应该也很多人都知道。
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。
本文主要记录了通过 Python 使用 OCR 的两次尝试。
Tesseract
Tesseract,一款由 HP 实验室开发由 Google 维护的开源 OCR(Optical Character Recognition , 光学字符识别)引擎,特点是开源,免费,支持多语言,多平台。
项目地址:https://github.com/tesseract-ocr/tesseract
安装使用
Tesseract 的安装比较简单,在 mac 可以通过 brew 安装。
1
brew install --with-training-tools tesseract
在 windows 可以通过 exe 安装包安装,下载地址可以从 GitHub 项目中的 wiki 找到。安装完成后记得将 Tesseract 执行文件的目录加入到 PATH 中,方便后续调用。
另外,默认安装会包含英文语言训练包,如果需要支持简体中文或者繁体中文,需要在安装时勾选。
或者安装结束后到项目地址下载:https://github.com/tesseract-ocr/tessdata
下载好的语言包放入到安装目录中的 testdata 下即可。在 windows 系统你还需要将 testdata 目录也加入环境变量。
1
TESSDATA_PREFIX=C:\Program Files (x86)\Tesseract-OCR\tessdata
如果一切就绪,你在命令行中就可以使用 Tesseract 命令。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# tesseract
Usage:
tesseract --help | --help-psm | --help-oem | --version
tesseract --list-langs [--tessdata-dir PATH]
tesseract --print-parameters [options...] [configfile...]
tesseract imagename|stdin outputbase|stdout [options...] [configfile...]
OCR options:
--tessdata-dir PATH Specify the location of tessdata path.
--user-words PATH Specify the location of user words file.
--user-patterns PATH Specify the location of user patterns file.
-l LANG[+LANG] Specify language(s) used for OCR.
-c VAR=VALUE Set value for config variables.
Multiple -c arguments are allowed.
--psm NUM Specify page segmentation mode.
--oem NUM Specify OCR Engine mode.
NOTE: These options must occur before any configfile.
通过命令行你就可以完成简单的图片文字识别任务。
1
tesseract test.png outfile -l chi_sim
通过 Python 调用
Tesseract 安装完成后可以很方便的被 Python 调用,你需要安装两个包。
1
2
pip install pillow
pip install pytesseract
一个简单的图片转文字的函数实现如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
from PIL import Image
import pytesseract
class Languages:
CHS = 'chi_sim'
CHT = 'chi_tra'
ENG = 'eng'
def img_to_str(image_path, lang=Languages.ENG):
return pytesseract.image_to_string(Image.open(image_path), lang)
print(img_to_str('image/test1.png', lang=Languages.CHS))
print(img_to_str('image/test2.png', lang=Languages.CHS))
测试图片- test1.png:

识别结果:
1
2
3
4
5
6
7
8
process image file "image/test1.png" in 1.4782530478747697 seconds
8 所 调 人 , 在 - 方 。
深 从 久 , 定 中 央
。 所 澈 伊 人 , 圭 水 淳
。 淇 渡 从 之 , 定 圭 北 中 坂 。
。 所 澈 伊人 , 圭 水 浩
从 丿 , 定 圭 水 中 沥 。
测试图片 - test2.png

识别结果:
1
2
3
4
process image file "image/test2.png" in 1.2131140296607923 seconds
清 明 时 节 雨 纷 纷 , 路 上 行 人 欲 断 魂
信 问 酒 家 何 处 有 , 牧 奕 通 指 枪 花 村 。
小结
Tesseract 在识别清晰的标准中文字体效果还行,稍微复杂的情况就很糟糕,而且花费的时间也很多,我个人觉得唯一的优点就是免费了。如果你不介意多花时间,可以考虑使用它提供的训练功能自定义你的语言库,那样在特定场景下识别率应该能上一个台阶。
百度云 OCR
这是偶然的发现,百度云提供了一定额度的免费的 OCR API,目前是每日 500 次,做做研究或者小应用还勉强够用,本文主要为了测试其效果。
文档地址:https://cloud.baidu.com/doc/OCR/OCR-Python-SDK.html
安装使用
首先你需要注册一个百度云 BCE 账号,然后从控制面板新建一个文字识别应用。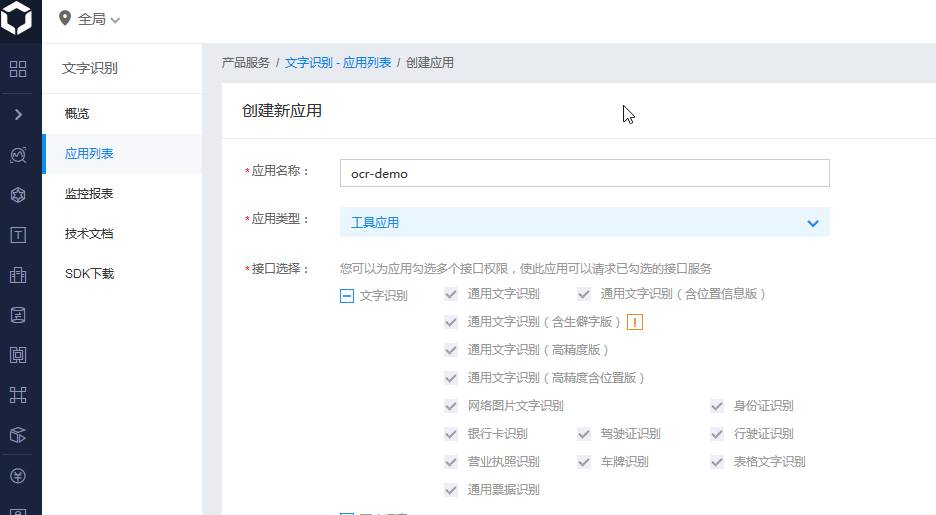
之后你就可以获得调用 API 需要的 AppID,API Key 和 Secret Key。后面只要根据官方文档一步一步走就可以了。
1
pip install baidu-aip
封装和调用
参考文档: https://cloud.baidu.com/doc/OCR/OCR-Python-SDK.html#.E6.8E.A5.E5.8F.A3.E8.AF.B4.E6.98.8E
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from aip import AipOcr
config = {
'appId': 'your-id',
'apiKey': 'your-key',
'secretKey': 'your-secret-key'
}
client = AipOcr(**config)
def get_file_content(file):
with open(file, 'rb') as fp:
return fp.read()
def img_to_str(image_path):
image = get_file_content(image_path)
result = client.basicGeneral(image)
if 'words_result' in result:
return '\n'.join([w['words'] for w in result['words_result']])
测试图片- test1.png:
识别结果:
1
2
3
4
5
6
7
8
9
10
process image file "image/test1.png" in 0.6331169034812572 seconds
蒹葭
先秦:佚名
蒹葭苍苍,白露为霜。所谓伊人,在水一方。
溯洄从之,道阻且长。溯游从之,宛在水中央。
蒹葭萋萋,白露未晞。所谓伊人,在水之湄。
溯洄从之,道阳且跻。溯游从之,宛在水中坻。
蒹葭采采,白露未已。所谓伊人,在水之涘。
溯洄从之,道阻且右。溯游从之,宛在水中沚。
测试图片 - test2.png
识别结果:
1
2
3
4
process image file "image/test2.png" in 0.6621812639450142 seconds
清明时节雨纷纷,路上行人欲断魂。
借问酒家何处有,牧童遥指杏花村。
小结
测试结果很明显,我只能说百度云这个 OCR 真是挺厉害的,一个错别字都没有,不服不行。论中文,还是百度比谷歌更懂一点。而且百度 OCR 提供了更多的参数让你更灵活的处理图片,比如自定义旋转,返回可信度,特定类型证件识别等等。
更多的 OCR
除了本文提到的 OCR,其实还是有不少其他选择。有一些直接提供 Demo 页面,你直接上传一张图片就可以直接看到识别效果,比如:
- 微软 Azure 图像识别:https://azure.microsoft.com/zh-cn/services/cognitive-services/computer-vision/
- 有道智云文字识别:http://aidemo.youdao.com/ocrdemo
- 阿里云图文识别:https://www.aliyun.com/product/cdi/
- 腾讯 OCR 文字识别: https://cloud.tencent.com/product/ocr
你有没有发现所有的大公司都有这样的服务?以后我们买买买就行,花大力气去发明轮子就没多大意义了。